
MinerU
1 引言
文档内容分析一直是计算机视觉领域的重要研究方向。尽管在 OCR、布局检测和公式识别等方面取得了显著进展,但现有的开源解决方案由于文档类型和内容的多样性,往往难以 consistently 提供高质量的内容提取。为了应对这些挑战,我们提出了 MinerU,一款开源的高精度文档内容提取解决方案。MinerU 利用 PDF-Extract-Kit 模型有效提取多样化文档的内容,并通过精细调优的预处理和后处理规则确保最终结果的准确性。实验结果表明,MinerU 在各种文档类型上 consistently 实现了高性能,显著提升了内容提取的质量和一致性。MinerU 开源项目可在 https://github.com/opendatalab/MinerU 获取。
ChatGPT 的发布于 2022 年底引发了对大语言模型(LLMs)研究的热潮。随着 LLMs 的快速发展,互联网网页数据已不足以支持模型训练的进一步提升。文档数据作为蕴含丰富知识的资源,成为增强 LLMs 的关键资源。检索增强生成(RAG)的引入进一步加剧了对高质量文档提取的需求。
目前,文档内容提取主要有四种技术方法:
OCR 基于的文本提取:使用 OCR 模型直接从文档中提取文本。虽然适用于纯文本文档,但在包含图像、表格、公式等元素时会引入大量噪声,不适合高质量数据提取。
库基于的文本解析:对于非扫描文档,使用 PyMuPDF 等开源 Python 库直接读取内容,无需调用 OCR,提供更快更准确的文本结果。但在包含公式、表格等元素时失效。
多模块文档解析:采用多种文档解析模型分阶段处理文档图像。首先,布局检测算法识别不同区域,如图像、图像标题、表格、表格标题、标题和文本。随后,对这些特定区域应用不同识别器。例如,对文本和标题使用 OCR,对公式使用公式识别模型,对表格使用表格识别模型。虽然理论上能产生高质量文档结果,但现有开源模型往往仅专注于学术论文,在教科书、试卷、研究报告和报纸等多样文档类型上表现不佳。
端到端 MLLM 文档解析:随着多模态大语言模型(MLLMs)的进步,涌现出许多文档内容提取模型,如 Donut、Nougat、Kosmos-2.5、Vary 等。这些模型受益于不断优化的编码器(如 SwinTransformer、ViTDet)和解码器(如 mBART、Qwen2-0.5B)以及数据工程,逐渐提升提取性能。但仍面临数据多样性和高推理成本的挑战。
为了更好地提取多样化文档,同时确保低推理成本和高推理质量,我们提出了 MinerU,一款一体化的文档提取工具。MinerU 的主要技术方法基于多模块文档解析策略。与现有文档解析算法不同,MinerU 利用 PDF-Extract-Kit 的各种开源模型,这些模型在多样化真实世界文档上训练,以实现复杂布局和复杂公式的任务中的高质量结果。在从模型获取不同区域的位置和识别内容后,MinerU 采用定制的处理工作流确保结果的准确性。
使用 MinerU 进行文档提取具有以下优势:
适应多样化文档布局:支持广泛的文档类型,包括但不限于学术论文、教科书、试卷和研究报告。
内容过滤:允许过滤无关区域,如页眉、页脚、脚注和侧边注释,提升文档可读性。
准确分割:结合基于模型和基于规则的后处理进行段落识别,实现跨列和跨页段落合并。
鲁棒页面元素识别:准确区分公式、表格、图像、文本块及其相应标题。
2 MinerU 框架
如图 1 所示,MinerU 处理多样化的用户输入 PDF 文档,并通过一系列步骤将其转换为所需的机器可读格式(Markdown 或 JSON)。具体而言,MinerU 的处理工作流分为四个阶段: 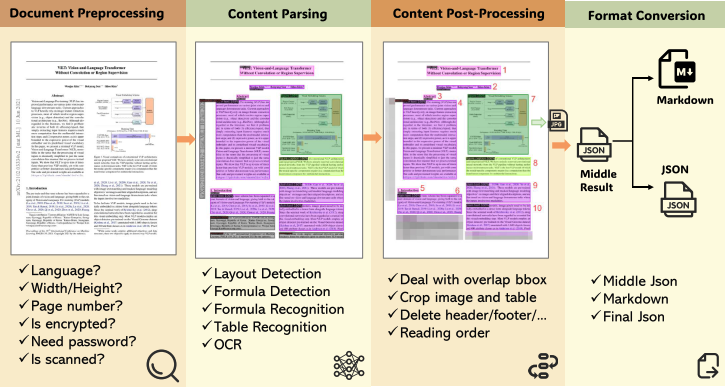
文档预处理:使用 PyMuPDF 读取 PDF 文件,过滤不可处理的文档,并提取 PDF 元数据,包括文档的可解析性(分为可解析和扫描 PDF)、语言类型和页面尺寸。
文档内容解析:采用 PDF-Extract-Kit,一款高质量 PDF 文档提取算法库,解析关键文档内容。首先进行布局分析,包括布局和公式检测。随后,对不同区域应用不同识别器:对文本和标题使用 OCR,对公式使用公式识别,对表格使用表格识别。
文档内容后处理:基于第二阶段的输出,移除无效区域,根据区域定位信息拼接内容,最终获取不同文档区域的定位、内容和排序信息。
格式转换:基于文档后处理的结果,生成用户所需的各种格式,如 Markdown。
2.1 文档预处理
PDF 文档预处理有两个主要目标:首先,过滤不可处理的 PDF,如非 PDF 文件、加密文档和密码保护文档。其次,获取 PDF 元数据以供后续使用。PDF 元数据的获取包括以下方面:
语言识别:目前,MinerU 仅识别和处理中文和英文文档。语言类型需要在执行 OCR 时指定为参数,其他语言的处理质量不保证。
内容乱码检测:一些基于文本的 PDF 在复制时文本显示乱码。此类 PDF 需要提前识别,以便在下一步中使用 OCR 进行文本识别。
扫描 PDF 识别:对于基于文本的 PDF(相对于扫描 PDF),MinerU 直接使用 PyMuPDF 进行文本提取。但对于扫描 PDF,需要启用 OCR。扫描 PDF 根据图像区域大于文本区域、甚至覆盖整个 PDF 页面以及每页平均文本长度接近零等特征识别。
页面元数据提取:提取文档元数据,如总页数、页面尺寸(宽度和高度)等。
2.2 文档内容解析
在文档解析阶段,MinerU 使用 PDF-Extract-Kit 模型库检测不同类型的区域并识别相应区域内容(OCR、公式识别、表格识别等)。PDF-Extract-Kit 是一款 PDF 解析算法库,包含各种最先进的开源 PDF 文档解析算法。与其他开源算法库不同,PDF-Extract-Kit 旨在构建一个模型库,确保在处理真实世界场景中的多样化数据时具有准确性和速度。当特定领域的 SOTA 开源算法无法满足实际需求时,PDF-Extract-Kit 使用数据工程构建高质量、多样化数据集进行进一步模型微调,从而显著提升模型对多样化数据的鲁棒性。MinerU 当前版本使用五个模型:布局检测、公式检测、表格识别、公式识别和 OCR。
2.2.1 布局分析
布局分析是文档解析的关键第一步,旨在区分页面上不同类型的元素及其相应区域。现有的布局检测算法在论文类型文档上表现良好,但在教科书和试卷等多样化文档上挣扎。因此,PDF-Extract-Kit 构建多样化布局检测训练集并训练高质量模型进行文档区域提取。
基于数据工程的模型训练方法如下:
多样化数据选择:收集多样化 PDF 文档,基于视觉特征聚类,并从不同聚类中心采样数据,获得初始多样化文档数据集。类别包括科学论文、一般书籍、教科书、试卷、杂志、PPT、研究报告等。
数据标注:对文档组件涉及的布局标注类型进行分类,包括标题、正文段落、图像、图像标题、表格、表格标题、图像表格注释、内联公式、公式标签和丢弃类型(页眉、页脚、页码和页面注释)。为每种类型建立详细标注标准,并标注约 21K 数据点作为训练集。
模型训练:基于布局检测模型微调模型。修改类别数量参数以与我们的分类布局类型对齐。
迭代数据选择和模型训练:在模型迭代期间,将部分数据作为验证集,并使用其结果指导后续数据迭代的重点。如果特定来源的 PDF 文档的特定类别得分低,则在下一次迭代中增加包含该特定类别的 PDF 页面的采样权重,从而更高效地迭代数据和模型。
在多样化数据集上训练的模型在多样化文档上表现显著更好。如图 2 所示,在教科书等文档上,基于多样化布局检测数据训练的布局检测模型表现优异,远超开源 SOTA 模型的性能。
2.2.2 公式检测
布局分析可以准确定位文档中的大多数元素,但公式类型,尤其是内联公式,在视觉上可能与文本无法区分,如 "100cm²" 和 "(α₁, α₂, ..., αₙ)"。如果不提前检测公式,后续使用 OCR 或 Python 库进行文本提取可能导致乱码文本,影响整体文档准确性,这对科学文档至关重要。因此,我们训练了一个专用公式检测模型。
对于公式检测数据集标注,我们定义了三个类别:内联公式、显示公式和忽略类别。忽略类别主要指难以确定为公式的区域,如 "50%"、"NaCl" 和 "1-2 days"。最终,我们在中文和英文论文、教科书、书籍和财务报告的 2,890 页上标注了 24,157 个内联公式和 1,829 个显示公式用于训练。
获得多样化公式检测数据集后,PDF-Extract-Kit 训练基于 YOLO 的模型,在各种文档上在速度和准确性方面表现良好。
2.2.3 公式识别
多样化文档包含各种类型的公式,如简短印刷内联公式和复杂显示公式。有些文档是扫描的,导致公式内容噪声,甚至存在手写公式。因此,MinerU 采用自研 UniMERNet 模型进行公式识别。UniMERNet 模型在大规模多样化公式识别数据集 UniMER-1M 上训练。由于模型结构的优化,它在真实世界场景中的各种类型公式(SPE、CPE、SCE、HWE)上实现了良好性能,与商业软件 MathPix 相当。
2.2.4 表格识别
表格是呈现结构化数据的有效方式,适用于科学出版物、财务报告、发票、网页等。提取视觉表格图像中的表格数据,即表格识别任务,具有挑战性,因为表格往往包含复杂的列和行标题,以及跨越单元格操作。通过 MinerU,用户可以执行 Table-to-LaTeX 或 Table-to-HTML 任务,从表格中提取结构化数据。
MinerU 采用 TableMaster 和 StructEqTable 进行表格识别任务。TableMaster 使用 PubTabNet 数据集(v2.0.0)训练,而 StructEqTable 使用 DocGenome 基准数据训练。TableMaster 将表格识别任务分为四个子任务,包括表格结构识别、文本行检测、文本行识别和框分配,而 StructEqTable 以端到端方式执行表格识别任务,展示更强的识别性能,即使在复杂表格上也能提供良好结果。
2.2.5 OCR
排除文档中的特殊区域(表格、公式、图像等)后,我们可以直接对文本区域应用 OCR 进行识别。MinerU 使用集成到 PDF-Extract-Kit 中的 Paddle-OCR 进行文本识别。然而,如图 3 所示,直接对整个页面进行 OCR 有时会导致不同列的文本被识别为单列,从而导致错误的文本顺序。因此,我们基于布局分析检测的文本区域(标题、文本段落)进行 OCR,以避免破坏阅读顺序。
如图 4 所示,在对包含内联公式的文本块执行 OCR 时,我们首先使用公式检测模型提供的坐标遮罩公式,然后执行 OCR,最后将公式重新插入 OCR 结果。 
2.3 文档内容后处理
后处理阶段主要解决内容排序问题。由于模型输出的文本、图像、表格和公式框可能重叠,以及 OCR 或 API 获取的文本行经常重叠,对文本和元素进行排序构成重大挑战。此阶段专注于处理边界框(BBox)之间的关系。
图 5 显示了解决重叠边界框前后结果的可视化。  BBox 关系解决方案包括以下方面:
BBox 关系解决方案包括以下方面:
包含关系:移除图像和表格区域内的公式和文本块,以及公式框内的框。
部分重叠关系:部分重叠的文本框垂直和水平收缩以避免相互覆盖,确保最终位置和内容不受影响,便于后续排序操作。对于文本与表格/图像之间的部分重叠,通过暂时忽略图像和表格确保文本完整性。
解决嵌套和部分重叠 BBox 后,MinerU 开发了一种基于人类阅读顺序的分割算法:"从上到下,从左到右"。此算法将整个页面分为几个区域,每个区域包含多个 BBox,同时确保每个区域最多包含一列。这确保文本按行从上到下阅读,遵循自然人类阅读序列。然后,根据位置关系对分割组进行排序,确定 PDF 中每个元素的阅读顺序。
2.4 格式转换
为适应用户对输出格式的不同需求,MinerU 将处理的 PDF 数据存储在中间结构中。中间结构是一个大型 JSON 文件,最重要的字段如表 1 所示。
| 字段名称 | 功能 |
|---|---|
| pdf_info | 此字段包含多个子字段。最重要的是 para_blocks,一个有序数组,其中每个元素代表 PDF 上的内容段,可以是图像、图像标题、文本、标题、表格等。连接此数组的内容可以重建 PDF 的内容(排除页眉、页脚、页码等)。 |
| _parse_type | 取值为 txt 或 ocr。如果是 txt,表示文本通过 API 直接从 PDF 提取。如果是 ocr,表示文本通过 OCR 引擎获取。 |
| _version_name | 软件版本,可用于跟踪数据处理中的错误。 |
表 1:中间结构中的重要字段
MinerU 的命令行支持输出 Markdown 和自定义 JSON 格式,两者均从上述中间结构转换。在格式转换过程中,可以根据需要裁剪图像、表格等元素。详细格式描述请参考文档 https://github.com/opendatalab/MinerU/blob/master/docs/output_file_en_us.md。
3 MinerU 质量评估
为评估 MinerU 从 PDF 中提取内容的质量,我们探索两个维度。首先,我们对负责文档内容解析的核心模块进行独立评估,以确保模型推理结果的准确性。模型结果的质量对最终内容质量至关重要,如整体过程所证实。在此阶段,我们具体评估三个模块:布局检测、公式检测和公式识别。我们构建多样化评估数据集,并将 MinerU 的 PDF-Extract-Kit 核心算法组件与其他最先进的开源模型进行比较。此外,我们进行手动质量检查以评估 MinerU 在多样化文档类型上的性能。
3.1 构建多样化评估数据集
为评估真实世界场景中的文档内容提取质量,我们最初构建了多样化评估数据集用于模型评估和提取内容的可视分析。如表 2 所示,多样化数据集包括 11 种文档类型,我们进一步从中构建布局检测和公式检测的评估数据集。
| 类别 | 描述 |
|---|---|
| 研究报告 | 来自互联网的财务报告,特征为大型表格、复杂合并表格、水平表格与文本混合、单双列以及复杂布局。 |
| 标准教科书 | 来自互联网的教科书,特征为单列布局、黑白颜色、嵌套复杂公式和大矩阵。 |
| 特殊图文教科书 | 来自互联网的具有特殊图文内容的教科书,涵盖英语、数学和中国(包括拼音)科目。 |
| 学术论文 | 来自 arXiv 和 SCIHUB 的文档,特征为复杂布局,包括单双列、图表和公式。 |
| 图册 | 来自互联网的图册,特征为包含大型图像的页面。 |
| PowerPoint 幻灯片 | 来自互联网的 PowerPoint 转换为 PDF 的文件,特征为背景颜色,涵盖生物、中国、英语和物理科目。 |
| 标准试卷 | 来自互联网的试卷,特征为考试布局、黑白背景,涵盖计算机科学、数学和中国,包括小学、中学、高中和行业题库。 |
| 特殊图文试卷 | 来自互联网的具有特殊图文内容的试卷,涵盖英语、数学和中国(包括拼音)科目。 |
| 历史文档 | 来自互联网的文档,特征为垂直布局、从右到左阅读顺序和繁体中文字体。 |
| 笔记 | 来自互联网的笔记,特征为手写内容,包括三个中学生的笔记。 |
| 标准书籍 | 来自互联网的书籍,特征为单列布局和黑白背景。 |
表 2:文档类别及其描述
3.2 核心算法模块评估
3.2.1 布局检测
我们将 MinerU 的布局检测模型与其他开源模型进行比较,包括 DocXchain、Surya 和来自 360LayoutAnalysis 的两个模型。表 3 显示了每个模型在学术论文和教科书验证集上的性能。LayoutLMv3-SFT 模型如表所示,是基于 LayoutLMv3-base-chinese 预训练模型,在我们内部构建的布局检测数据集上微调的。布局检测的初始评估数据集包括学术论文和教科书的验证集。
| 模型 | 学术论文 Val | 教科书 Val | ||||
|---|---|---|---|---|---|---|
| mAP | AP50 | AR50 | mAP | AP50 | AR50 | |
| DocXchain | 52.8 | 69.5 | 77.3 | 34.9 | 50.1 | 63.5 |
| Surya | 24.2 | 39.4 | 66.1 | 13.9 | 23.3 | 49.9 |
| 360LayoutAnalysis-Paper | 37.7 | 53.6 | 59.8 | 20.7 | 31.3 | 43.6 |
| 360LayoutAnalysis-Report | 35.1 | 46.9 | 55.9 | 25.4 | 33.7 | 45.1 |
| LayoutLMv3-Finetuned (Ours) | 77.6 | 93.3 | 95.5 | 67.9 | 82.7 | 87.9 |
表 3:不同模型在布局检测上的性能
3.2.2 公式检测
我们将 MinerU 的公式检测模型与开源公式检测模型 Pix2Text-MFD 进行比较。此外,YOLO-Finetuned 是我们基于 YOLOv8 使用多样化公式检测训练集训练的模型。
公式检测评估数据集由学术论文和各种来源的页面组成,用于公式检测。结果如表 4 所示,表明在多样化数据上微调的检测模型在论文和其他各种文档类型上显著优于以前的开源模型。
| 模型 | 学术论文 Val | 多源 Val | ||
|---|---|---|---|---|
| AP50 | AR50 | AP50 | AR50 | |
| Pix2Text-MFD | 60.1 | 64.6 | 58.9 | 62.8 |
| YOLOv8-Finetuned (Ours) | 87.7 | 89.9 | 82.4 | 87.3 |
表 4:不同模型在公式检测上的性能
3.2.3 公式识别
PDF 包含各种类型的公式,为在多样化公式上实现鲁棒的公式识别结果,我们使用 UniMERNet 作为公式识别模型。鉴于同一公式可能有各种表达式,我们使用 CDM 评估公式识别性能。如表 5 所示,UniMERNet 的公式识别能力远超其他开源模型,并与 Mathpix 等商业软件相当。
| 模型 | ExpRate | ExpRate@CDM | BLEU | CDM |
|---|---|---|---|---|
| Pix2tex | 0.1237 | 0.291 | 0.4080 | 0.636 |
| Texify | 0.2288 | 0.495 | 0.5890 | 0.755 |
| Mathpix | 0.2610 | 0.5 | 0.8067 | 0.951 |
| UniMERNet | 0.4799 | 0.811 | 0.8425 | 0.968 |
表 5:不同模型在 UniMER-Test 数据集上的评估结果。结果改编自 CDM 论文。ExpRate 和 BLEU 指标以灰色显示,因为它们被认为不太可靠。CDM 指标不受公式表示多样性的影响,因此是比较不同模型公式识别性能的更合理指标。
基于上述评估,我们可以得出结论:MinerU 使用的模型,专门在多样化文档来源上训练,显著优于为单一文档类型设计的其他开源模型,确保解析结果的准确性。
3.3 端到端结果可视化和分析
为评估 MinerU 最终提取结果的质量,除了确保上述模型提取结果的质量外,我们还对提取结果进行后处理,如移除噪声内容和拼接模型输出。MinerU 的后处理操作确保最终结果的可读性和准确性。如图 7 所示,MinerU 在多样化文档上实现了优秀提取结果。
从可视化结果可以看出,布局检测结果准确定位不同区域。跨度显示公式检测和 OCR 检测结果令人满意,最终拼接成高质量 Markdown 结果。
4 结论和未来工作
在这项工作中,我们介绍了 MinerU,一款一站式 PDF 文档提取工具。由于高质量模型推理结果和细致的预处理和后处理操作,MinerU 即使在处理多样化文档类型时也能确保高质量提取结果。虽然 MinerU 已展现显著优势,但仍有很大改进空间。未来,我们将在以下领域持续升级 MinerU:
核心组件增强:我们将迭代更新 PDF-Extract-Kit 中的现有模型,进一步提升多样化文档的提取质量。此外,我们将引入新模型,如表格识别和阅读顺序,以增强 MinerU 的整体能力。
可用性和推理速度改进:我们将进一步优化 MinerU 的处理管道,以加速文档提取速度并增强可用性。此外,我们将部署更高效的在线推理服务,以满足用户的实时需求。
系统基准构建:我们将建立多样化文档的系统评估基准,以清晰比较 MinerU 与最先进开源方法的結果,帮助社区用户选择最适合其需求的模型。