
上下文工程
1 引言
上下文(Context)对于 AI Agent 来说是一种关键但有限的资源。在本文中,我们将探讨如何有效地策划和管理为 Agent 提供动力的上下文。
在应用 AI 领域,经过几年对提示工程(Prompt Engineering)的关注后,一个新的术语开始崭露头角:上下文工程(Context Engineering)。使用语言模型(LLM)进行构建,不再仅仅是为提示词寻找合适的措辞,而是更多地回答一个更广泛的问题:“什么样的上下文配置最有可能产生我们模型预期的行为?”
上下文指的是从大语言模型(LLM)采样时包含的 Token 集合。当前的工程问题是如何在 LLM 的固有约束下优化这些 Token 的效用,以持续实现预期的结果。有效地驾驭 LLM 通常需要“在上下文中思考”——换句话说:考虑 LLM 在任何给定时间可用的整体状态,以及该状态可能产生什么潜在行为。
2 上下文工程 vs 提示工程
在 Anthropic,我们将上下文工程视为提示工程的自然演进。
- 提示工程:指编写和组织 LLM 指令以获得最佳结果的方法(例如编写有效的系统提示词)。
- 上下文工程:指在 LLM 推理过程中策划和维护最佳 Token 集合(信息)的策略,包括所有可能落在提示词之外的其他信息(系统指令、工具、模型上下文协议 MCP、外部数据、消息历史记录等)。
在 LLM 工程的早期,提示(Prompting)是 AI 工程工作中最大的组成部分,因为大多数用例都需要针对单次分类或文本生成任务进行优化的提示。然而,随着我们通过多次推理和更长的时间范围来构建能力更强的 Agent,我们需要管理整个上下文状态的策略。
Agent 在循环中运行时会生成越来越多可能与下一次推理相关的数据,这些信息必须经过循环提炼。上下文工程是一门艺术和科学,即从不断演变的可能信息宇宙中,策划出什么将进入有限的上下文窗口。
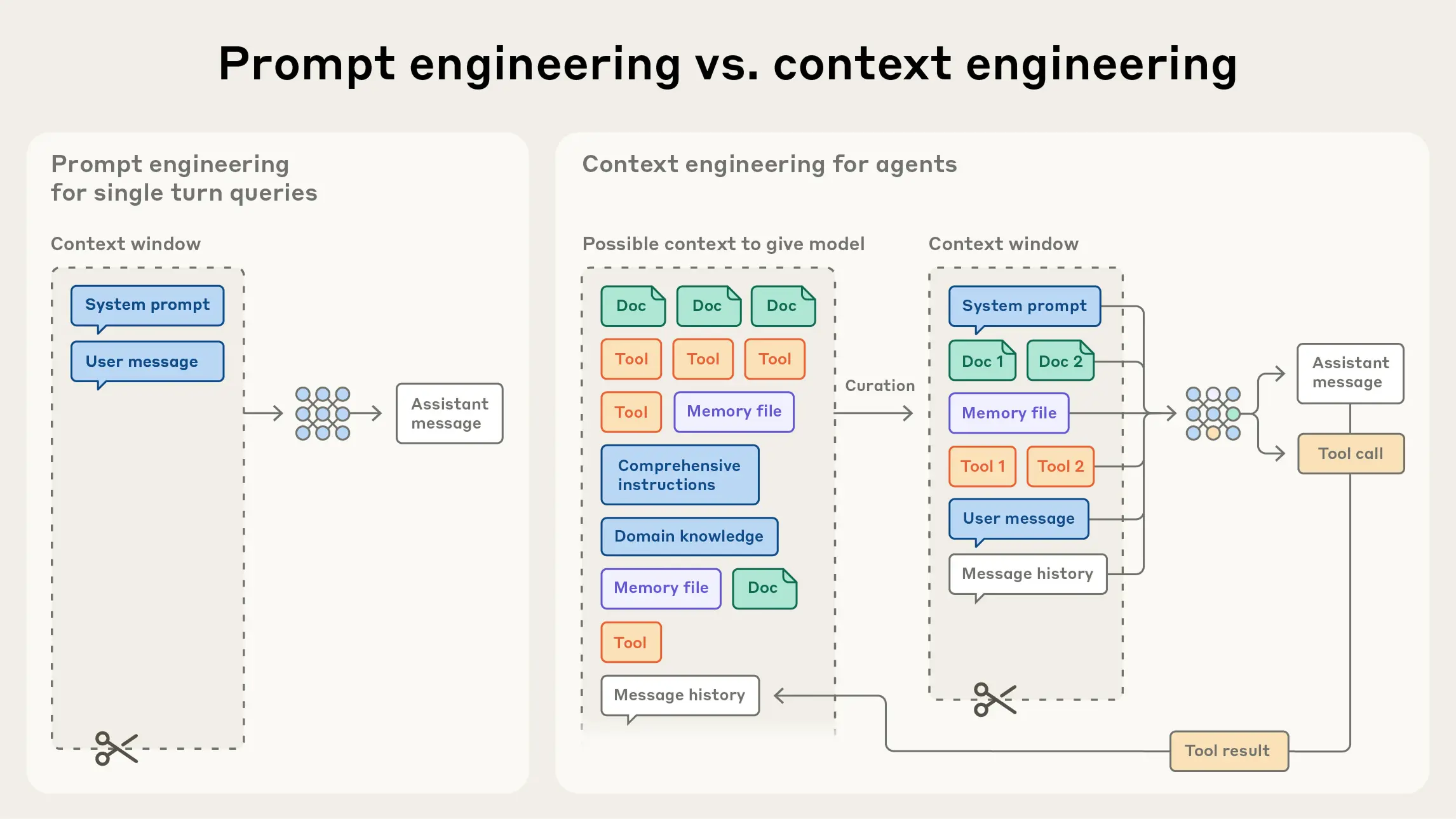
与编写提示的离散任务相比,上下文工程是迭代的,并且策划阶段发生在我们每次决定传递什么给模型时。
3 为什么上下文工程至关重要
尽管 LLM 处理数据的速度和能力在不断提升,但我们观察到,像人类一样,LLM 在达到一定程度后也会失去焦点或感到困惑。关于“大海捞针”(needle-in-a-haystack)式基准测试的研究揭示了 上下文腐烂(Context Rot) 的概念:随着上下文窗口中 Token 数量的增加,模型从该上下文中准确回忆信息的能力会下降。
上下文必须被视为一种具有边际收益递减的有限资源。就像人类的工作记忆容量有限一样,LLM 在解析大量上下文时也有一个“注意力预算(Attention Budget)”。每一个新引入的 Token 都会消耗一定的预算,从而增加了仔细策划 LLM 可用 Token 的必要性。
这种注意力稀缺源于 LLM 的架构约束。LLM 基于 Transformer 架构,该架构使每个 Token 都能关注整个上下文中的每一个其他 Token。这导致了 个 Token 之间存在 的成对关系。
随着上下文长度的增加,模型捕捉这些成对关系的能力会被拉伸变薄,在上下文大小和注意力焦点之间产生自然的张力。此外,模型从训练数据分布中发展出注意力模式,而在训练数据中,较短的序列通常比较长的序列更常见。这意味着模型在处理上下文范围的依赖关系方面经验较少,专用参数也较少。
这些现实意味着,深思熟虑的上下文工程对于构建能力强的 Agent 至关重要。
4 有效上下文的解剖
鉴于 LLM 受到有限注意力预算的限制,优秀的上下文工程意味着找到 最小的高信号 Token 集合,以最大化实现预期结果的可能性。
4.1 系统提示词(System Prompts)
系统提示词应极其清晰,并使用简单、直接的语言,以适合 Agent 的“高度”呈现想法。合适的“高度”是介于两种常见失败模式之间的“金发姑娘区(Goldilocks zone)”:
- 极端一:工程师在提示词中硬编码复杂、脆弱的逻辑。这会导致脆弱性并增加维护复杂性。
- 极端二:工程师提供模糊、高层的指导,未能给 LLM 提供具体的信号,或错误地假设了共享上下文。
最佳的高度在两者之间取得了平衡:足够具体以有效地指导行为,又足够灵活以为模型提供强大的启发式方法来指导行为。
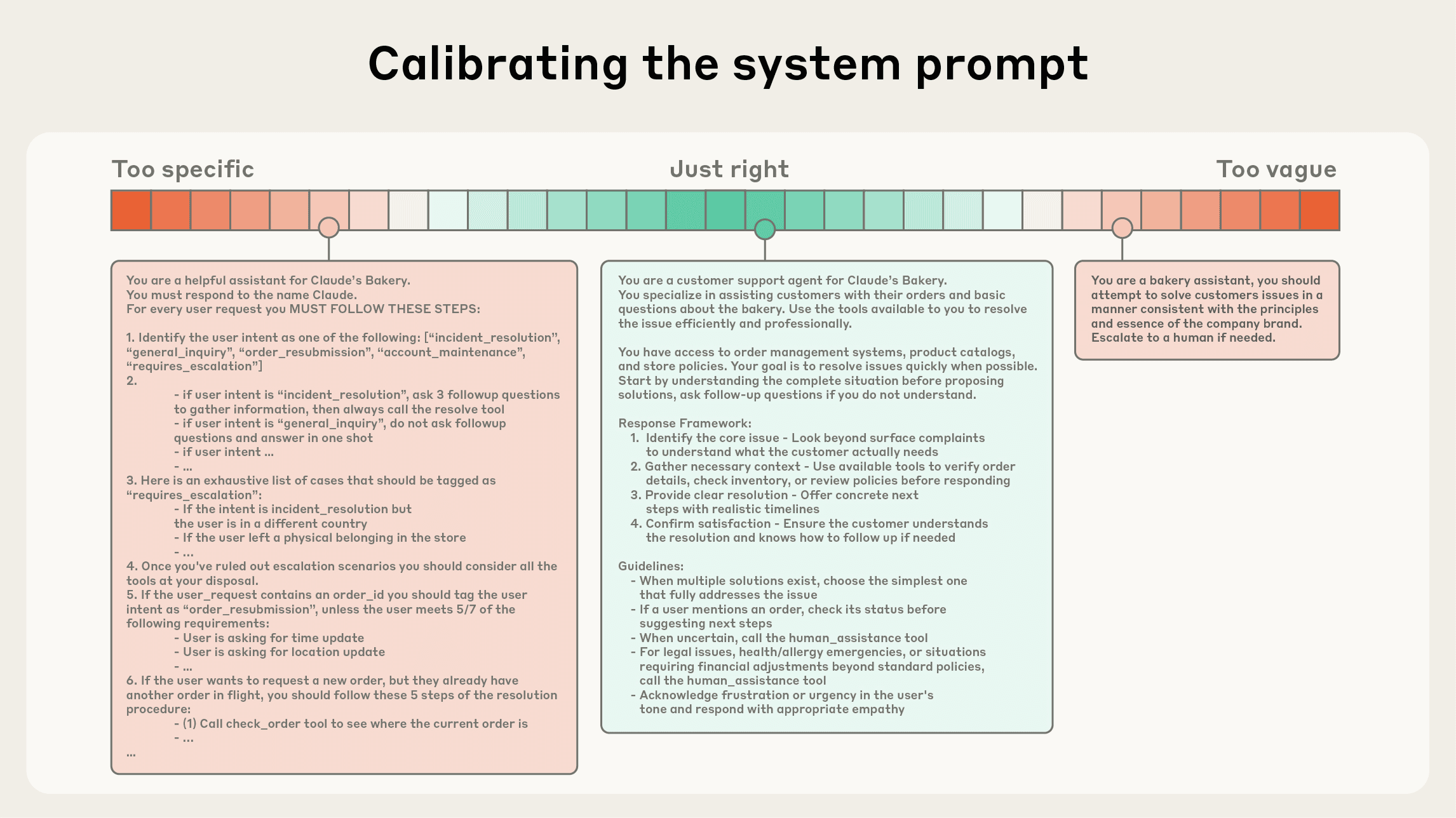
我们建议将提示词组织成不同的部分(如 <background_information>, <instructions>, ## Tool guidance, ## Output description 等),并使用 XML 标签或 Markdown 标题等技术来划分这些部分。
4.2 工具(Tools)
工具允许 Agent 与其环境进行操作并在工作时引入新的、额外的上下文。因为工具定义了 Agent 与其信息/行动空间之间的契约,所以工具必须促进效率,既要返回 Token 高效的信息,又要鼓励高效的 Agent 行为。
工具应该:
- 自包含且对错误鲁棒。
- 用途极其清晰。
- 输入参数描述性强且无歧义。
我们常见的一个失败模式是工具集过于庞大,涵盖了过多的功能,或者导致关于使用哪个工具的决策点模棱两可。如果人类工程师无法明确地说出在给定情况下应该使用哪个工具,那么就不能指望 AI Agent 做得更好。策划一个最小可行工具集(Minimal Viable Set)也有助于在长时间交互中更可靠地维护和修剪上下文。
4.3 示例(Examples)
提供示例(即少样本提示,Few-shot prompting)是一个众所周知的最佳实践。然而,团队通常会在提示词中塞入一长串边缘案例,试图阐明 LLM 应遵循的每一条规则。我们 不推荐 这样做。
相反,我们建议策划一组 多样化的、规范的示例,有效地描绘 Agent 的预期行为。对于 LLM 来说,示例是胜过千言万语的“图片”。
5 上下文检索与 Agent 搜索
我们现在看到工程师在设计 Agent 上下文时的思维方式发生了转变。许多 AI 原生应用采用某种形式的基于嵌入(Embedding)的预推理检索(RAG)来呈现重要的上下文。随着领域向更具 Agent 特性的方法过渡,我们越来越多地看到团队使用 “即时(Just-in-time)” 上下文策略来增强这些检索系统。
5.1 即时上下文策略
与其预先处理所有相关数据,不如让 Agent 维护轻量级的标识符(文件路径、存储的查询、Web 链接等),并使用这些引用在运行时使用工具动态地将数据加载到上下文中。
Anthropic 的 Agent 编码解决方案 Claude Code 就使用了这种方法来对大型数据库执行复杂的数据分析。模型可以编写有针对性的查询,存储结果,并利用像 head 和 tail 这样的 Bash 命令来分析大量数据,而无需将完整的数据对象加载到上下文中。这种方法反映了人类的认知:我们通常不会背诵整个语料库的信息,而是引入外部组织和索引系统(如文件系统、收件箱和书签)来按需检索相关信息。
5.2 渐进式披露(Progressive Disclosure)
让 Agent 自主导航和检索数据还实现了渐进式披露——换句话说,允许 Agent 通过探索增量地发现相关上下文。
- 文件大小 暗示复杂性。
- 命名约定 暗示用途。
- 时间戳 可以作为相关性的代理。
Agent 可以一层一层地构建理解,只在工作记忆中保留必要的内容,并利用笔记策略进行额外的持久化。这种自我管理的上下文窗口使 Agent 专注于相关的子集,而不是淹没在详尽但可能无关的信息中。
当然,这存在权衡:运行时探索比检索预计算数据要慢。此外,需要有主见且深思熟虑的工程设计,以确保 LLM 拥有正确的工具和启发式方法来有效地导航其信息景观。
在某些设置中,最有效的 Agent 可能采用 混合策略:为了速度预先检索一些数据,并根据其判断进行进一步的自主探索。
6 长周期任务的上下文工程
长周期任务要求 Agent 在 Token 计数超过 LLM 上下文窗口的动作序列中保持连贯性、上下文和目标导向行为。对于跨越数十分钟到数小时连续工作的任务(如大型代码库迁移或综合研究项目),Agent 需要专门的技术来绕过上下文窗口大小的限制。
我们开发了几种直接解决这些上下文污染约束的技术:压缩(Compaction)、结构化笔记(Structured note-taking) 和 子 Agent 架构(Multi-agent architectures)。
6.1 压缩(Compaction)
压缩是指获取接近上下文窗口限制的对话,总结其内容,并使用该摘要重新启动一个新的上下文窗口的做法。压缩通常作为上下文工程的第一个杠杆,以驱动更好的长期连贯性。
在 Claude Code 中,我们通过将消息历史记录传递给模型来总结和压缩最关键的细节来实现这一点。模型保留架构决策、未解决的 Bug 和实现细节,同时丢弃多余的工具输出或消息。然后,Agent 可以带着这个压缩的上下文加上最近访问的五个文件继续工作。
压缩的艺术在于选择保留什么与丢弃什么。对于实施压缩系统的工程师,我们建议在复杂的 Agent 轨迹(Trace)上仔细调整您的提示词。
6.2 结构化笔记(Structured note-taking)
结构化笔记,或称 Agent 记忆,是一种技术,Agent 定期将笔记持久化到上下文窗口之外的内存中。这些笔记会在稍后的时间被拉回上下文窗口。
这种策略以最小的开销提供了持久性记忆。就像 Claude Code 创建待办事项列表,或者您的自定义 Agent 维护一个 NOTES.md 文件一样,这种简单的模式允许 Agent 跨复杂任务跟踪进度,维护关键上下文和依赖关系,否则这些信息会在数十次工具调用中丢失。
6.3 子 Agent 架构(Sub-agent architectures)
子 Agent 架构提供了另一种绕过上下文限制的方法。与其让一个 Agent 试图跨整个项目维护状态,不如让专门的子 Agent 处理具有干净上下文窗口的特定任务。
主 Agent 协调高层计划,而子 Agent 执行深度技术工作或使用工具查找相关信息。每个子 Agent 可能会进行广泛的探索,使用数万个 Token 或更多,但只返回其工作的浓缩、提炼的摘要(通常为 1,000-2,000 个 Token)。
这种方法的选择取决于任务特征:
- 压缩 保持了需要广泛来回的任务的对话流畅性。
- 笔记 擅长具有明确里程碑的迭代开发。
- 多 Agent 架构 处理复杂的并行探索能带来红利的研究和分析。
7 结论
上下文工程代表了我们使用 LLM 构建方式的根本转变。随着模型变得越来越强大,挑战不仅仅是制作完美的提示词,而是深思熟虑地策划在每一步进入模型有限注意力预算的信息。
无论您是为长周期任务实施压缩,设计 Token 高效的工具,还是让 Agent 即时探索其环境,指导原则保持不变:找到最小的高信号 Token 集合,以最大化实现预期结果的可能性。
原文链接:https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents