
RAGAS
1. RAGAS 的核心概念
RAGAS(Retrieval-Augmented Generation Assessment Score)是一个专门用于评估 RAG(Retrieval-Augmented Generation,检索增强生成)系统性能的开源评估框架。它的核心价值在于能够在无需人工标注的情况下,自动化地评估检索模块和生成模块的质量,为 RAG 系统的优化提供量化指标。
该框架主要关注两个核心问题:
- 检索质量:检索到的上下文是否准确、相关且完整?
- 生成质量:基于检索结果生成的答案是否忠实、相关且有用?
2. RAGAS 的输入与输出
2.1 输入数据结构
RAGAS 的输入是一组问答记录(QA Pairs),每条记录包含以下字段:
| 字段名 | 类型 | 必需性 | 说明 |
|---|---|---|---|
question | string | 必需 | 用户提出的问题 |
answer | string | 必需 | RAG 系统生成的回答 |
contexts | list[string] | 必需 | 检索模块返回的文本片段列表 |
ground_truth | string | 可选 | 人工标注的标准答案,用于对比评估 |
一个典型的输入示例:
{
"question": "什么是向量数据库?",
"answer": "向量数据库是一种专门用于存储和检索高维向量数据的数据库系统...",
"contexts": [
"向量数据库(Vector Database)是专为处理向量嵌入而设计的...",
"常见的向量数据库包括 Pinecone、Weaviate、Milvus 等...",
],
"ground_truth": "向量数据库是用于高效存储和检索向量嵌入的专用数据库...",
}2.2 输出评估指标
RAGAS 会为每条样本计算多个维度的评分,并可以汇总生成整体平均分:
| 指标名称 | 评分范围 | 依赖字段 | 评估维度 |
|---|---|---|---|
faithfulness | 0~1 | answer, contexts | 答案是否忠实于检索到的上下文 |
answer_relevancy | 0~1 | question, answer | 答案是否真正回答了问题 |
context_precision | 0~1 | question, contexts, ground_truth | 检索结果的精确度和排序质量 |
context_recall | 0~1 | ground_truth, contexts | 检索结果是否覆盖真实答案的要点 |
context_relevancy | 0~1 | question, contexts | 检索到的上下文与问题的整体相关度 |
评估结果示例:
{
"faithfulness": 0.95,
"answer_relevancy": 0.88,
"context_precision": 0.82,
"context_recall": 0.90,
"context_relevancy": 0.85,
}3. 核心评估指标详解
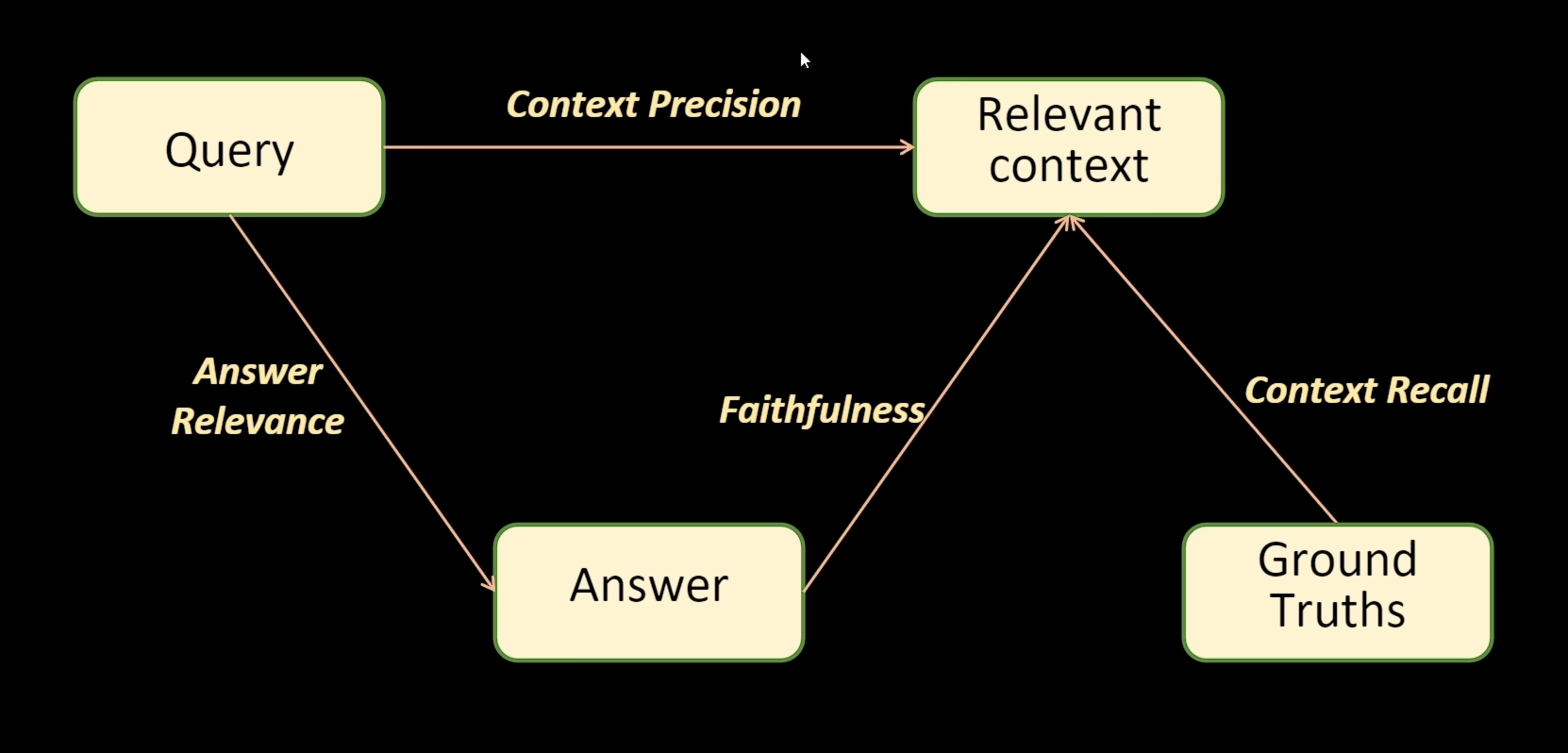
3.1 Faithfulness(忠实度)
定义:衡量生成的答案与检索到的上下文之间的事实一致性程度。
评估原理:RAGAS 会将答案分解为多个陈述(claims),然后逐一验证每个陈述是否能从给定的上下文中检索出来。忠实度分数等于被上下文支持的陈述数量与总陈述数量的比值。
计算公式:
评估流程:
示例:
假设 RAG 系统生成的答案是:"Python 是由 Guido van Rossum 在 1991 年创建的,它是一种解释型语言。"
- 陈述 1:Python 是由 Guido van Rossum 创建的 ✓(上下文支持)
- 陈述 2:Python 在 1992 年创建 (上下文不支持)
- 陈述 3:Python 是解释型语言 ✓(上下文支持)
Faithfulness = 2/3 = 0.67
注意事项:忠实度低可能意味着模型产生了幻觉(hallucination),即生成了上下文中不存在的信息。
3.2 Answer Relevancy(答案相关性)
定义:评估生成的答案是否真正回答了用户提出的问题,是否包含冗余或无关信息。
评估原理:RAGAS 采用逆向验证的方法。它会基于生成的答案反向生成若干个可能的问题,然后计算这些生成问题与原始问题的相似度。如果答案确实相关,那么根据答案生成的问题应该与原问题高度相似。
计算公式:
其中 是基于答案生成的第 个问题, 是生成的问题数量。
评估流程:
降分因素:
- 答案不完整,未充分回答问题
- 答案包含大量冗余信息
- 答案偏离问题主题
3.3 Context Precision(上下文精确度)
定义:衡量检索到的上下文片段中,真正相关的内容占比,以及相关内容是否被排在靠前的位置。
评估原理:Context Precision 关注检索结果的排序质量。在理想情况下,与问题最相关的上下文片段应该排在列表的前面。该指标会检查每个位置上的上下文片段是否与标准答案(ground truth)相关。
计算公式:
Context Precision 采用加权平均精确度的方式计算,考虑了相关项在检索结果中的位置。首先计算每个位置 k 的精确度:
然后对所有位置的精确度进行加权平均,只有当该位置的项相关时才计入权重:
其中 是位置 处的相关性指示器(相关为 1,不相关为 0)。这个公式确保相关项排在越前面,得分越高。
示例说明:
假设检索到 5 个上下文片段,按照相关度从高到低排序,真实相关的片段为1、2、4,标记为相关(R)或不相关(N):
| 位置 | 相关性 | Precision@k |
|---|---|---|
| 1 | R | 1/1 = 1.0 |
| 2 | R | 2/2 = 1.0 |
| 3 | N | 2/3 = 0.67 |
| 4 | R | 3/4 = 0.75 |
| 5 | N | 3/5 = 0.6 |
Context Precision = (1.0×1 + 1.0×1 + 0.67×0 + 0.75×1 + 0.6×0) / 3 = 0.92
重要性:高精确度意味着检索系统能够准确定位相关信息,减少噪声干扰。
3.4 Context Recall(上下文召回率)
定义:衡量标准答案中的关键信息有多少能够在检索到的上下文中找到。
评估原理:RAGAS 会将标准答案(ground truth)分解为多个句子或陈述,然后检查每个陈述是否能从检索到的上下文中找到依据。召回率等于被上下文支持的陈述比例。
计算公式:
其中 GT 表示 Ground Truth(标准答案)。
评估流程:
示例:
标准答案:"Python 是一种高级编程语言,由 Guido van Rossum 创建,广泛用于数据科学。"
- 陈述 1:Python 是高级编程语言 ✓(上下文包含)
- 陈述 2:由 Guido van Rossum 创建 ✓(上下文包含)
- 陈述 3:广泛用于数据科学 ✗(上下文未提及)
Context Recall = 2/3 = 0.67
意义:低召回率说明检索系统遗漏了重要信息,需要优化检索策略或扩大检索范围。
3.5 Context Relevancy(上下文相关性)
定义:评估检索到的上下文内容与问题的整体相关程度。
评估原理:该指标关注检索结果中有用信息的比例。它会计算上下文中与问题相关的句子数量占总句子数量的比例。
计算公式:
与 Context Precision 的区别:
- Context Relevancy 关注内容本身的相关性比例
- Context Precision 关注相关内容的排序质量
4. RAG 系统整体评估框架
RAGAS 从检索和生成两个维度对 RAG 系统进行全面评估:
4.1 评估维度划分
| 评估阶段 | 相关指标 | 关注点 |
|---|---|---|
| 检索阶段 | Context Precision, Context Recall, Context Relevancy | 检索结果的准确性、完整性和相关性 |
| 生成阶段 | Faithfulness, Answer Relevancy | 生成内容的忠实度和问题匹配度 |
4.2 实际应用建议
诊断检索问题:
- Context Recall 低 → 扩大检索范围或改进查询重写
- Context Precision 低 → 优化重排序算法或调整相似度阈值
- Context Relevancy 低 → 改进向量化模型或检索策略
诊断生成问题:
- Faithfulness 低 → 调整生成模型的提示词,强调基于上下文回答
- Answer Relevancy 低 → 优化生成模型的指令跟随能力
综合优化:
- 监控各指标的变化趋势
- 识别瓶颈环节(检索 vs 生成)
- 进行针对性的系统优化
5. 使用示例
from ragas import evaluate
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_precision,
context_recall,
)
# 准备评估数据
data = {
"question": ["什么是 RAG?", "如何评估 RAG 系统?"],
"answer": ["RAG 是检索增强生成...", "可以使用 RAGAS 框架..."],
"contexts": [
["RAG 结合了检索和生成...", "它能提高回答准确性..."],
["RAGAS 提供多个评估指标...", "包括忠实度和相关性..."],
],
"ground_truth": ["RAG 是一种结合检索和生成的技术", "RAGAS 是评估 RAG 的工具"],
}
# 执行评估
result = evaluate(
data,
metrics=[
faithfulness,
answer_relevancy,
context_precision,
context_recall,
],
)
print(result)6. 总结
RAGAS 为 RAG 系统提供了一套完整的自动化评估方案,通过多维度指标帮助开发者:
- 量化系统性能:用客观数据替代主观判断
- 定位问题环节:明确是检索还是生成出现问题
- 指导优化方向:基于指标变化进行针对性改进
- 降低评估成本:减少对人工标注的依赖
在实际应用中,建议根据具体业务场景选择合适的指标组合,并结合人工评估进行交叉验证,以获得更全面的系统评估结果。